Data governance bepaalt of uw data daadwerkelijk veilig is, niet de tooling, niet de cloudprovider en niet AI op zichzelf.
Organisaties met volwassen data governance lopen aantoonbaar minder risico op datalekken, compliance-boetes en reputatieschade.
Toch denken veel bedrijven nog steeds dat dataveiligheid vooral een technisch vraagstuk is. Extra firewalls, een nieuwe cloudomgeving of een AI-tool met “enterprise security” lijken voldoende. De realiteit is anders. De grootste datalekken van de afgelopen jaren laten één patroon zien: het ontbreekt aan duidelijke afspraken, eigenaarschap en controle over data.
In dit artikel leggen we stap-voor-stap uit:
wat data governance écht is
wat er misging bij bekende datalekken
wat AI met uw data doet
waarom EU-wetgeving dit onderwerp urgenter maakt
en waarom gespecialiseerde data-analisten en engineers cruciaal zijn
Wat is data governance en waarom bepaalt het hoe veilig mijn data is?
Data governance is het geheel aan afspraken, rollen, processen en technische maatregelen dat bepaalt wie data mag gebruiken, wijzigen, opslaan en beveiligen.
Zonder data governance is dataveiligheid afhankelijk van toeval en individuele kennis.
Concreet gaat data governance over vragen als:
Wie is eigenaar van deze data?
Wie mag erbij en waarom?
Waar staat deze data opgeslagen?
Hoe lang bewaren we dit?
Hoe tonen we compliance aan?
Veel organisaties hebben tooling, maar geen eenduidig antwoord op deze vragen. En precies daar ontstaan risico’s.
Een data engineer verwoordde het op Reddit (r/dataengineering) treffend:
“We hadden enterprise tooling, maar niemand wist wie verantwoordelijk was voor de data zelf. Governance ontbrak volledig.”
Bijna elke organisatie gebruikt AI-tools, vaak zonder te beseffen wat dit betekent voor hun data
AI is al lang geen experiment meer, maar dagelijkse praktijk
Vrijwel elke organisatie gebruikt vandaag AI-tools, of dat nu formeel is toegestaan of niet. Medewerkers werken met ChatGPT om teksten samen te vatten, gebruiken Copilot om code te genereren, laten AI meedenken over analyses en delen bestanden via Teams, Slack en andere samenwerkingsplatformen. Dat gebeurt niet op één afdeling, maar organisatiebreed. En meestal sneller dan beleid of governance kan bijbenen.
Wat dit zo risicovol maakt, is dat deze tools worden ingezet vanuit gemak en productiviteit, niet vanuit dataveiligheid. Voor de gebruiker voelt het alsof hij “even helpt met denken”. Voor de organisatie betekent het dat data wordt gekopieerd, geanalyseerd, opgeslagen en soms hergebruikt, vaak buiten het zicht van IT, security of compliance.
Waarom dit een blinde vlek is voor veel organisaties
De meeste organisaties beseffen wél dat data waardevol is, maar onderschatten wat er gebeurt zodra AI-tools en collaboration platforms structureel onderdeel worden van het werk. Een prompt in een AI-tool kan gevoelige klantinformatie bevatten. Een document in Teams of Slack kan automatisch worden samengevat, doorzocht of gekoppeld aan andere data. En wat eenmaal gedeeld is, kan zich sneller verspreiden dan men verwacht.
Het probleem is niet dat deze tools bestaan, maar dat er zelden expliciet is vastgelegd wat wel en niet mag. Wie mag welke data invoeren in AI? Welke data mag worden gedeeld in chattools? Hoe lang blijven die gegevens beschikbaar? En wie controleert dat eigenlijk? In veel organisaties is het eerlijke antwoord: niemand weet het precies.
Wat zijn de grootste datalekken van de afgelopen jaren en wat leren we daarvan?
De grootste datalekken zijn zelden het gevolg van geavanceerde hacks, maar bijna altijd van falende data governance.
Onvoldoende toegangsbeheer, gebrekkige monitoring en onduidelijk eigenaarschap liggen structureel aan de basis.
Chronologisch overzicht van impactvolle datalekken
Jaar | Organisatie | Wat ging er mis | Governance-les |
|---|---|---|---|
2017 | Ongepatchte kwetsbaarheid, 147M records | Geen ownership & patchbeleid | |
2018 | Misbruik API-toegang (Cambridge Analytica) | Geen dataminimalisatie | |
2020 | Marriott | Onvoldoende segmentatie systemen | Slechte data-classificatie |
2023 | MOVEit | Supply-chain kwetsbaarheid | Geen keten-governance |
Volgens de European Union Agency for Cybersecurity ontstaat meer dan 60% van de datalekken door interne fouten, niet door externe aanvallen.
Een security engineer op r/netsec:
“We hadden encryptie, MFA en monitoring. Maar niemand wist wie verantwoordelijk was voor dataretentie. Dat werd ons datalek.”
Welke risico’s loopt mijn organisatie zonder goede data governance?
Zonder data governance is het onmogelijk om structureel grip te houden op data, compliance en security.
De risico’s nemen exponentieel toe zodra organisaties werken met cloud, analytics en AI.
Veelvoorkomende risico’s:
te brede toegangsrechten
shadow IT en ongeautoriseerde tools
onzichtbare datastromen
onduidelijke bewaartermijnen
onvolledige audit-trails
Bij audits of incidenten blijkt dan vaak dat niemand het volledige overzicht heeft.
Wat doet AI eigenlijk met mijn data?
AI-tools verwerken, combineren en analyseren data, vaak buiten het zicht van de organisatie.
Zonder duidelijke governance verliest u controle over waar data wordt opgeslagen, hoe lang die wordt bewaard en wie toegang heeft.
AI-systemen:
loggen prompts en metadata
verwerken data in externe omgevingen
gebruiken input soms voor modelverbetering
koppelen data aan gebruikersaccounts
Onderzoek van onder andere de University of Oxford toont aan dat data in AI-systemen vaak langer bewaard blijft dan organisaties verwachten, wat directe AVG-risico’s oplevert.
👉 Verdieping over AI en privacy.
Hoe vergroot AI het risico op datalekken?
AI vergroot datarisico’s doordat het data centraliseert, verrijkt en reproduceert.
Een verkeerde prompt of export kan leiden tot structureel dataverlies.
Typische AI-gerelateerde risico’s:
gevoelige data in prompts
trainingsdata met persoonsgegevens
exports uit AI-analytics tools
shadow AI (gebruik buiten IT om)
De European Data Protection Board waarschuwt dat AI zonder governance in strijd is met dataminimalisatie en doelbinding.
👉 Meer over EU-regelgeving voor jouw organisatie.
Waarom AI-soevereiniteit niet bestaat zonder data governance
AI-soevereiniteit bepaalt waar uw data technisch wordt opgeslagen, maar data governance bepaalt of u daar daadwerkelijk controle over heeft.
Zonder duidelijke governance verandert een ‘EU-cloud’ in niets meer dan een marketinglabel zonder juridische of operationele waarde.
Steeds meer organisaties kiezen bewust voor Europese cloud- en AI-alternatieven. Niet alleen vanwege kosten of prestaties, maar vooral door toenemende zorgen over privacy, datatoegang en buitenlandse wetgeving. Toch blijkt in de praktijk dat een migratie naar de EU zelden het onderliggende probleem oplost.
Wat organisaties vaak denken
“Als onze data in Europa staat, zijn we compliant.”
Wat er in werkelijkheid gebeurt
Zonder data governance:
blijven toegangsrechten te breed
ontbreekt inzicht in datastromen tussen systemen
is onduidelijk wie data mag gebruiken voor AI-toepassingen
blijft logging en verantwoording fragmentarisch
Met andere woorden: de locatie verandert, maar de risico’s blijven bestaan.
Inzichten uit ons eigen onderzoek onder data- en IT-professionals
AI-soevereiniteit begint niet bij beleid of cloudkeuze, maar bij wat professionals vandaag al wél en niet doen binnen hun organisatie.
Ons eigen onderzoek onder data- en IT-specialisten laat zien dat organisaties vooral in beweging zijn, maar nog nauwelijks in controle.
Om beter te begrijpen hoe organisaties omgaan met AI-soevereiniteit, cloudkeuzes en dataveiligheid, hebben wij bij Morgan Black een peiling uitgevoerd onder data- en IT-professionals. Daarbij stelden we één concrete vraag:
“Vervangen jullie als Data / IT-specialisten US-based tools door EU-alternatieven?”
De antwoorden laten zien dat het onderwerp niet theoretisch is, maar actief leeft op de werkvloer:
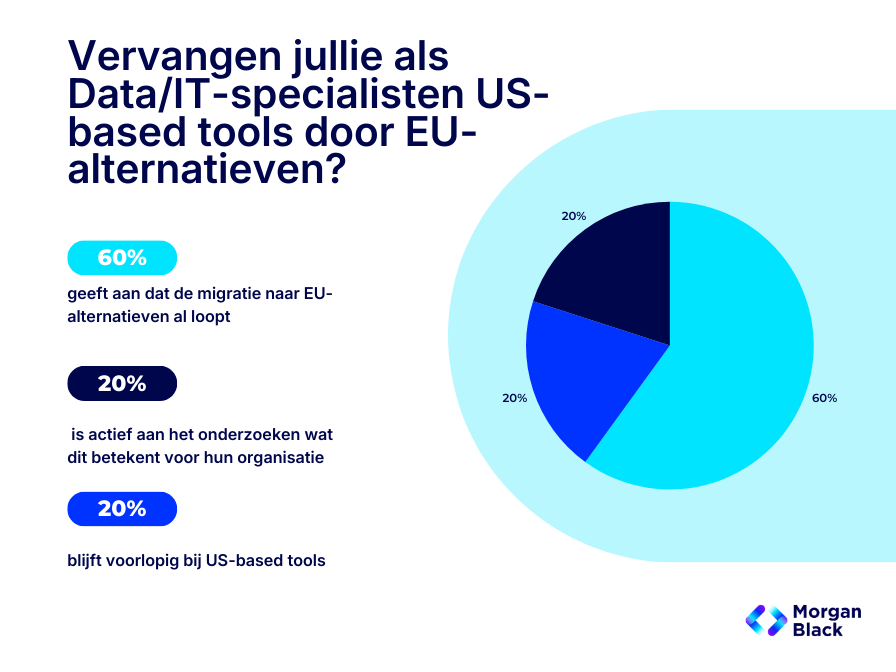
Deze cijfers sluiten nauw aan bij discussies in internationale data-communities. Data engineers waarschuwen daar expliciet dat soevereiniteit zonder governance een illusie is.
Een veelgehoorde reactie onder data-professionals:
“We verhuisden onze data naar een Europese cloudprovider, maar governance bleef ongewijzigd. Dezelfde mensen hadden dezelfde rechten, dezelfde exports en dezelfde risico’s. Compliance veranderde niets.”
Dit illustreert een cruciaal punt: soevereiniteit is geen technische migratie, maar een bestuurlijk en organisatorisch vraagstuk.
Wat zegt het dark web over mijn dataveiligheid?
Het dark web fungeert als een vroege waarschuwing voor falende data governance.
Veel organisaties ontdekken daar pas dat hun data al is uitgelekt.
Volgens het Nationaal Cyber Security Centrum worden veel datalekken pas ontdekt via externe signalen.
Veelvoorkomende vondsten:
hergebruikte wachtwoorden
oude database-exports
API-keys
interne datasets
Vraag je je af of jouw data op het darkweb staat?
Bekijk onze dark web-checklist en hoe je erachter komt via ons blog.
Hoe ziet een effectief data governance-framework eruit? (5 praktische stappen)
Een effectief data governance-framework zorgt ervoor dat data veilig, controleerbaar en compliant blijft, ook wanneer AI en cloudgebruik toenemen.
Organisaties die dit goed inrichten, combineren duidelijke verantwoordelijkheden met technisch afdwingbare controles.
Stap 1: Data-eigenaarschap vastleggen
Data is pas beheersbaar als duidelijk is wie er verantwoordelijk voor is.
Zonder expliciet data-eigenaarschap ontstaat onduidelijkheid bij incidenten, audits en datalekken.
In de praktijk betekent dit:
per dataset een formele data-eigenaar aanwijzen
onderscheid maken tussen business owner en technisch beheerder
vastleggen wie beslissingen mag nemen over gebruik, opslag en verwijdering
Zonder deze stap blijft governance persoonsafhankelijk en verdwijnt kennis bij personeelswisselingen.
Stap 2: Data classificeren op risico en impact
Niet alle data vraagt hetzelfde beveiligingsniveau.
Data-classificatie bepaalt hoe streng toegangsbeheer, logging en bewaartermijnen moeten zijn.
Een praktisch model bestaat meestal uit:
Publiek – vrij deelbaar, geen risico
Intern – bedrijfsgevoelig, beperkt toegankelijk
Vertrouwelijk – persoonsgegevens of strategische data
Zeer gevoelig – financiële, medische of wettelijke kerngegevens
Deze classificatie vormt de basis voor:
Stap 3: Toegangsbeheer afdwingen (least-privilege & RBAC)
Toegang tot data moet functioneel, tijdelijk en herleidbaar zijn.
Te ruime rechten zijn één van de grootste oorzaken van datalekken.
Effectief toegangsbeheer houdt in:
werken volgens het least-privilege principle
rolgebaseerde toegang (RBAC) in plaats van persoonsafhankelijk
periodieke review van toegangsrechten
automatische intrekking bij rolwisselingen
Data engineers spelen hier een sleutelrol door dit technisch af te dwingen, niet alleen vast te leggen.
Stap 4: Monitoring, logging en verantwoording
Zonder inzicht is governance niet aantoonbaar.
Monitoring en logging maken zichtbaar wie data gebruikt, wanneer en waarvoor.
Belangrijke elementen:
audit-trails voor data-toegang en wijzigingen
data lineage: waar komt data vandaan en waar gaat het naartoe?
incidentrespons-procedures bij afwijkingen
inzicht in AI-gebruik en exports
Dit is essentieel voor:
audits
compliance-rapportages
forensisch onderzoek bij datalekken
Stap 5: Continue evaluatie en volwassenwording
Data governance is geen eenmalig project, maar een continu proces.
Nieuwe tools, AI-toepassingen en wetgeving veranderen het speelveld constant.
Daarom vereist governance:
periodieke audits en herclassificatie
training van teams in datagebruik en AI-risico’s
evaluatie van tooling en leveranciers
bijstelling van beleid op basis van incidenten en inzichten
Organisaties die dit nalaten, zien governance langzaam verouderen: precies op het moment dat risico’s toenemen.
Waarom data governance zonder data-analisten en engineers onvermijdelijk faalt
Governance is geen documentprobleem, maar een uitvoeringsprobleem
Data governance gaat in de praktijk zelden mis omdat organisaties geen beleid hebben. Het gaat mis omdat niemand verantwoordelijk is voor de vertaling van dat beleid naar hoe data dagelijks wordt gebruikt. En precies op dat punt ontstaat urgentie. Want terwijl beleid achterloopt, groeit het gebruik van data en AI elke maand verder.
Van individuele handeling naar organisatiebreed risico
Wat begint als een individuele keuze: “ik gebruik even ChatGPT”, kan uitgroeien tot een organisatiebreed risico. AI-tools combineren en verrijken data automatisch. Collaboration platforms maken informatie laagdrempelig toegankelijk. Zonder governance ontstaat een situatie waarin data zich verplaatst zonder dat iemand overzicht houdt.
Dit is precies waarom klassieke beveiligingsmaatregelen tekortschieten. Firewalls en toegangsrechten beschermen systemen, maar niet wat medewerkers vrijwillig invoeren, delen of kopiëren. Governance is nodig om kaders te stellen vóórdat data in deze tools belandt, niet pas achteraf wanneer er vragen komen.
Waarom dit niet vanzelf goedkomt
Veel organisaties gaan ervan uit dat dit vanzelf wordt opgelost via nieuwe regelgeving, standaardinstellingen of updates van leveranciers. Dat is een gevaarlijke aanname. Leveranciers optimaliseren voor gebruiksgemak en adoptie, niet voor de specifieke governance-eisen van jouw organisatie. Zonder eigen kaders blijft controle afhankelijk van individuele keuzes van medewerkers.
Juist nu AI-tools zo breed worden gebruikt, ontstaat urgentie. Elke dag dat er geen duidelijke afspraken, technische beperkingen en monitoring zijn ingericht, groeit de hoeveelheid data die buiten formele controle valt. En hoe langer dat duurt, hoe moeilijker het wordt om achteraf inzicht en grip te krijgen.
Waarom dit opnieuw terugkomt bij data-analisten en data engineers
Dit is geen gedragsprobleem dat je oplost met een memo of training alleen. Het vraagt om mensen die begrijpen hoe data door systemen beweegt, hoe AI-tools data verwerken en hoe samenwerkingstools informatie verspreiden. Data-analisten en data engineers zijn degenen die kunnen vertalen waar risico’s ontstaan en hoe je die structureel voorkomt.
Zonder hun expertise blijft AI-gebruik een blinde vlek in governance. Met hen wordt het onderdeel van een beheersbaar, uitlegbaar en controleerbaar datalandschap.
Wat dit concreet betekent voor uw organisatie
Als AI- en datagebruik sneller groeien dan governance, ontstaat een structureel risico. Niet omdat medewerkers fouten maken, maar omdat niemand expliciet verantwoordelijk is voor de technische borging ervan. Dat is precies waar veel organisaties nu vastlopen.
De oplossing zit daarom niet in extra richtlijnen of bewustwording, maar in het inzetten van data-analisten en data engineers die governance kunnen vertalen naar de dagelijkse praktijk. Zolang die expertise ontbreekt, blijft grip op data afhankelijk van toeval.
👉 Wilt u weten welke data-specialisten nodig zijn om dit binnen uw organisatie structureel te borgen?
FAQ / De meest gestelde vragen rondom data veiligheid bij organisaties/bedrijven
1. Hoe bescherm ik mijn bedrijfsdata?
Je beschermt je bedrijfsdata door technische beveiliging te combineren met duidelijke processen en bewustwording bij medewerkers. Denk aan toegangsbeheer, versleuteling, back-ups en heldere afspraken over datagebruik.
Goede databescherming begint met inzicht: welke data heb je, waar staat die en wie mag erbij? Vervolgens zorg je voor sterke wachtwoorden, multi-factor authenticatie, actuele software en beveiligde netwerken. Minstens zo belangrijk is het trainen van medewerkers, omdat menselijke fouten vaak de oorzaak zijn van datalekken.
2. Welke datalek komt het meest voor?
Het meest voorkomende datalek ontstaat door menselijk handelen, zoals phishing, verkeerd verstuurde e-mails of zwakke wachtwoorden. Technische hacks komen voor, maar zijn minder vaak de primaire oorzaak.
Medewerkers klikken bijvoorbeeld op een phishinglink of delen per ongeluk gevoelige informatie met de verkeerde ontvanger. Daarom ligt de focus bij moderne informatiebeveiliging niet alleen op technologie, maar ook op gedrag, awareness en duidelijke richtlijnen.
3. Waarom is het gebruiken van een veilige AI-omgeving belangrijk?
Een veilige AI-omgeving voorkomt dat gevoelige bedrijfsinformatie onbedoeld wordt opgeslagen, gedeeld of hergebruikt. Zonder goede afspraken kan data die je invoert in AI-tools buiten je organisatie terechtkomen.
Veel AI-tools verwerken input om modellen te verbeteren of logs bij te houden. Als je daar vertrouwelijke klant- of bedrijfsdata invoert zonder beveiligde omgeving of contractuele afspraken, kan dit leiden tot datalekken, complianceproblemen en reputatieschade. Dit raakt direct aan je cloud- en datakeuzes, omdat “waar” en “hoe” data verwerkt wordt vaak bepalend is voor je risicoprofiel. Meer context over hoe je dit toekomstbestendig inricht vind je in ons blog over de veiligste cloud omgeving opties.
4. Wat is het verschil tussen data governance en data management?
Data governance gaat over wie verantwoordelijk is voor data en welke regels gelden, terwijl data management draait om de dagelijkse verwerking en opslag van data. Governance bepaalt het kader, management voert het uit.
Bij data governance stel je beleid op over eigenaarschap, kwaliteit, compliance en beveiliging. Data management richt zich op praktische zaken zoals databases, back-ups, integraties en datastromen. Beide zijn nodig om data veilig, betrouwbaar en bruikbaar te houden.
5. Wat zijn de 3 basisprincipes van informatiebeveiliging?
De drie basisprincipes van informatiebeveiliging zijn vertrouwelijkheid, integriteit en beschikbaarheid. Samen vormen zij de kern van vrijwel alle beveiligingsmaatregelen.
Vertrouwelijkheid betekent dat alleen bevoegden toegang hebben tot informatie. Integriteit zorgt ervoor dat data niet ongewenst wordt aangepast, en beschikbaarheid garandeert dat informatie toegankelijk is wanneer dat nodig is, bijvoorbeeld bij systemen of calamiteiten.
6. Welke AI-tools kan ik veilig gebruiken als organisatie?
Organisaties kunnen AI-tools veilig gebruiken als deze voldoen aan privacywetgeving, data niet hergebruiken voor training en duidelijke beveiligingsmaatregelen hebben. Enterprise- of zakelijke versies zijn daarbij altijd veiliger dan gratis varianten.
Let bij AI-tools op zaken als dataverwerking, opslaglocatie, toegangsrechten en auditmogelijkheden. Maak intern duidelijke richtlijnen: welke tools zijn toegestaan, voor welke taken en met welke soort data. Zo voorkom je schaduw-IT en ongecontroleerd datagebruik.
7. Is ChatGPT veilig om te gebruiken als bedrijf?
ChatGPT kan veilig worden gebruikt binnen een bedrijf, mits er duidelijke richtlijnen zijn en geen vertrouwelijke of persoonsgegevens worden gedeeld. De veiligheid hangt vooral af van hoe en in welke versie de tool wordt ingezet.
Voor zakelijk gebruik is het belangrijk om afspraken te maken over datagebruik, toegangsrechten en logging. Gratis of publieke AI-tools zijn minder geschikt voor gevoelige informatie; organisaties doen er goed aan om vast te leggen welke data wel en niet mag worden ingevoerd en dit actief te communiceren naar medewerkers. Lees meer hierover in ons blog “Hoe veilig is ChatGPT nou eigenlijk?”.
8. Welke alternatieven zijn er voor ChatGPT voor mijn bedrijf?
Er zijn meerdere AI-tools die zich beter laten beheren in zakelijke omgevingen met meer controle over data en privacy. De juiste keuze hangt af van je organisatiegrootte, budget en waarvoor je de tool wilt gebruiken.
Er zijn Europese AI-alternatieven voor ChatGPT die meer controle bieden over data, opslaglocatie en privacy. Deze tools zijn beter afgestemd op AVG-wetgeving en Europese compliance-eisen.
Mistral is een Europese AI-ontwikkelaar uit Frankrijk met sterke focus op open modellen, transparantie en Europese wetgeving. Hun modellen kunnen on-premise of in een Europese cloud worden ingezet, waardoor data binnen de EU blijft.
Aleph Alpha (Duitsland) richt zich expliciet op enterprise-AI, compliance en explainability. Wordt veel gebruikt door overheden en organisaties die hoge eisen stellen aan dataveiligheid en controle.
Silo AI ontwikkelt maatwerk AI-oplossingen voor bedrijven binnen Europa. Data blijft in private of Europese cloudomgevingen, wat deze optie geschikt maakt voor gevoelige bedrijfsinformatie.
Ionic AI biedt een ChatGPT-achtig platform, maar met focus op Europese dataopslag, privacy en zakelijke inzet. Geschikt voor organisaties die generatieve AI willen gebruiken zonder data buiten Europa te verwerken.
Private AI in eigen EU-cloud of on-premise omgeving
Sommige organisaties kiezen ervoor om open-source AI-modellen te draaien binnen hun eigen Europese cloud of datacenter. Dit biedt maximale controle over data, maar vraagt wel volwassen cloud-, security- en governance-inrichting.
Welke optie het meest geschikt is, hangt sterk samen met je cloudstrategie, dataclassificatie en governance-model. Zonder duidelijke afspraken over waar data wordt verwerkt en wie verantwoordelijk is, blijft AI een risico, ook met Europese tools.
Omdat Europese wetgeving rond AI zich snel ontwikkelt, is het verstandig om AI-gebruik ook formeel te borgen binnen beleid en standaarden: 👉 EU-standaarden rondom AI-tools.


